Pythonエンジニアにお勧めなHTTPライブラリ「requests」
「requests」という、HTTPライブラリの紹介になります。
HTTPとは?
HTTPとは、サーバとクライアントがHTML等の情報を送受信するためのルール、約束になります。
HTTPのHTは、Hypertextという意味ですが、これはHTMLのことと考えるとわかりやすいです。(実際にはHTMLに限らないですが)
Transferは転送、などの意味を持ち、Protocolは、手順、手続き、といった意味を持つ単語です。
つまり、HTMLの転送手順、などのような意味になります。
他にも、
・SMTP(Simple Mail Transfer Protocol) — 簡易メール転送プロトコル
・FTP(File Transfer Protocol) — ファイル転送プロトコル
・POP(Post Office Protocol) — 電子メールの受信
等のプロトコルがあります。
ウェブブラウザとサーバがやっているのもこのHTTPでの通信で、意識しなくても皆さんは使っていることでしょう。
ウェブブラウザに限らず、プログラムからあるウェブページにアクセスしたい、という場合があります。
例えば、最近よく聞く「スクレイピング」「クローラー」というものは、実際にウェブブラウザを立ち上げず(立ち上げるケースもあります)、
プログラム上でサーバにリクエストを行い、レスポンスを受け取り、必要なデータだけを高速に抜きだす…といった作業をします。
また、Web APIという、ブラウザではなくプログラムからHTTPリクエストを送ることを前提にしたものもあります。
Pythonには標準ライブラリにurllib2*1がありましたが、少々使いづらいものでした。
requestsは「HTTP for Humans」という説明のとおり、非常に使いやすく、わかりやすいです。
最近のPython書籍を見ても、HTTPでのやり取りを扱う場合はrequestsを使ってるようです。
*1 Python3では、urllib2はurllib.request, urllib.errorに分割されました。
サンプルコード
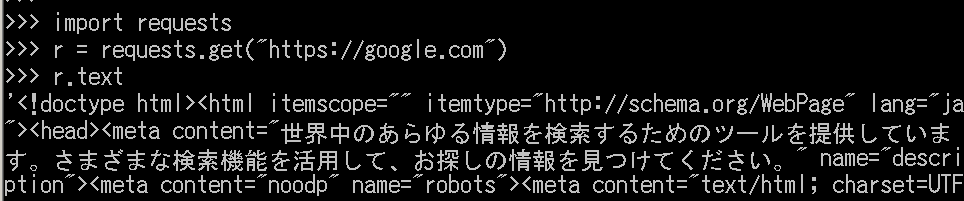
グーグルのトップページへGETメソッドでリクエストを送りたい場合は、以下のようにします。
import requests
r = requests.get("https://www.google.co.jp/")
ステータスコードやレスポンスボディ等は、以下のように取得が可能です。
print(r) # print(r.status_code) # 200 print(r.text) # レスポンスボディ print(r.content) # レスポンスボディのバイナリデータ
GETだけでなく、POST等他のメソッドも簡単に扱えます。
r = requests.post("https://www.google.co.jp/")
r = requests.head("https://www.google.co.jp/")
r = requests.put("https://www.google.co.jp/")
r = requests.delete("https://www.google.co.jp/")
POSTで、データを送信したい場合は以下のようになります。
data = {"firstname": "sato", "lastname": "taro"}
r = requests.post("http://sample.com/post", data=data)
プロキシやユーザーエージェントの設定等も簡単です。
proxies = {
"http": "1.1.1.1:8080",
"https": "1.1.1.1:8080",
}
headers = {
"User-Agent": "Mozilla/5.0 (Linux; U; Android 4.1.2; ja-jp; SC-06D Build/JZO54K) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30",
}
r = requests.get("http://test.com", headers=headers, proxies=proxies)
認証も非常に容易に行えます。
r = requests.get('http://auth.com', auth=('user', 'pass'))















